Member-only story
Data structure for file management application
Exploring advanced data structures

Introduction
The project idea
I want to create a file management application that can explore a file system through a web application, in the same way as Windows Explorer on Windows.
The application provides a graphical user interface for accessing and managing the file systems. It can handle all file operations, including creation, renaming, searching, deleting, and more.

My initial challenge is to determine the proper data structure for visualizing directories and files. The solution must have the ability to handle a large number of files.
The purpose of this article is to tackle this challenge. Let’s start by reviewing the standard data structures.
Limitations of standard data structures
To build a file manager, it is important to take into account several factors, such as the use of storage (disk or memory), the access time for random and sequential processing, as well as the efficiency of searches.
However, most standard data structures, such as arrays, linked lists, stacks, queues, and others, are near-optimal in one aspect but not efficient in another. Let’s look at the table below:
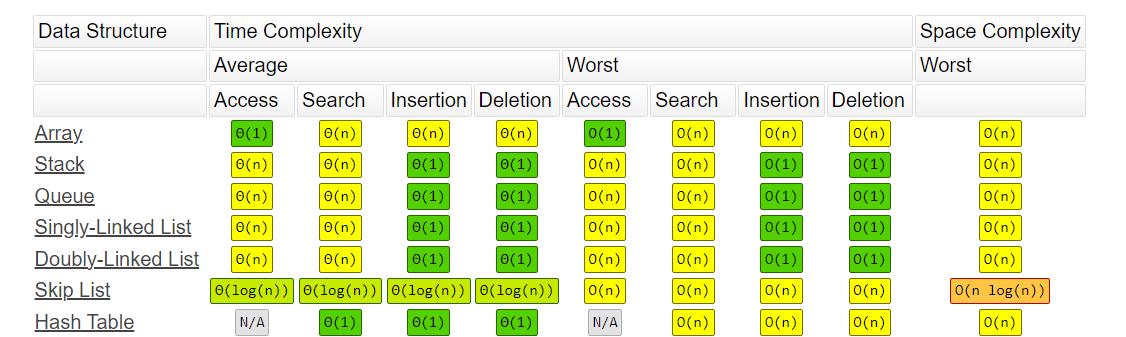
For example, while accessing an element of the array takes O(1), the other operations are greedy O(n). Similarly, the access and search time in Stack, Queue and Linked List takes O(n).
Keep in mind that the CPU time is calculated using this formula:
CPU Time = IC * CPI / Clock Rate
IC: Instruction Count of a program
CPI: Cycle per instructionThe more steps to run (instructions), the higher the CPU time and the worse the performance of the application.

